



<Segment>
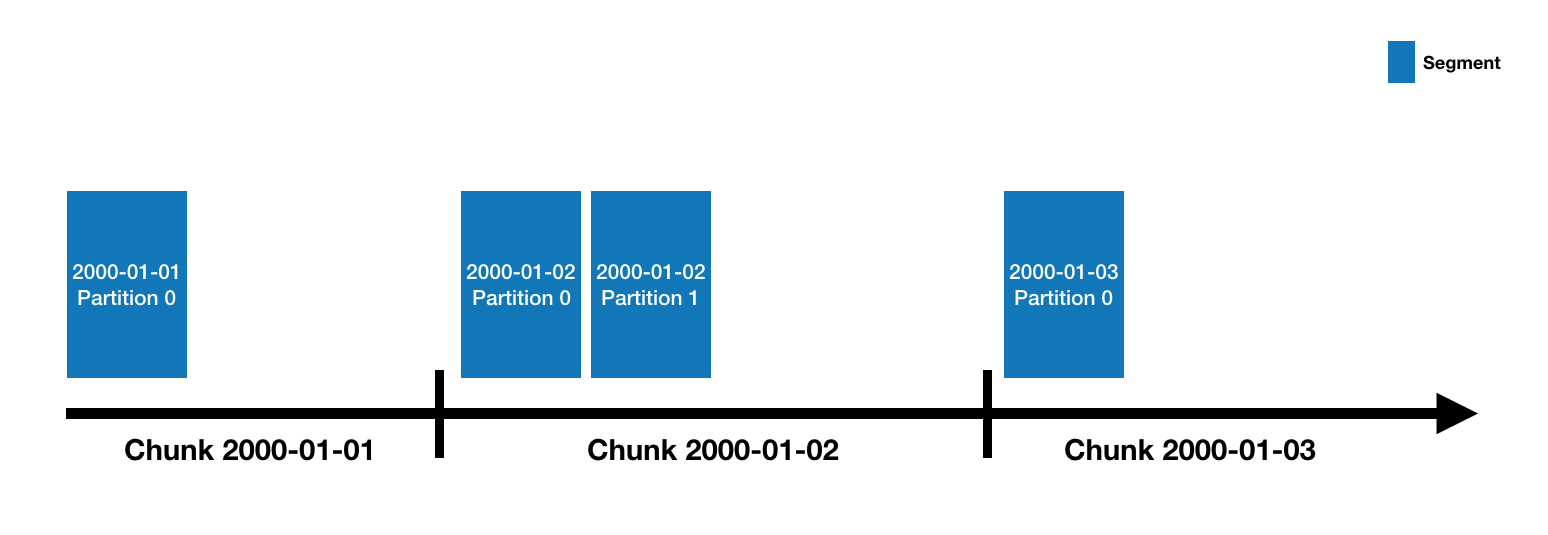
Segment는 위 그림과 같이 Druid에서 시간에 따라 파티셔닝된 데이터 단위이며, 데이터 구조는 아래와 같이 Timestamp/Dimensions/Metrics로 구성된다.

Segment 생성 시 시간 단위는 granularitySpec/partitionSpec 설정에 따라 결정되며, Reference에 따르면 300 MB ~ 700 MB / 5 million Rows가 추천하는 초기 설정값이라고 한다.
이 외에도 Segment는 shardSpec에 따라 샤딩될 수 있는데 전체 샤드를 포함하여 block이라 하며, Linear shard spec을 제외하면 전체 샤드가 생성되어야 Query 시 처리될 수 있다.
Segment는 ID로써 DataSource_Interval_Version_PartitionNumber 형태로 생성된다.
<Segment Availability>
Historical 프로세스 장애 시에는 해당 Historical을 Coordinator가 제외시키며, 제외된 Historical의 Segment들은 다른 Historical에 재할당한다.
하지만 즉각 재할당 되는 것이 아니라 일정 시간 내 해당 Historical이 Available 상태로 복구된다면, Segment 역시 복구된 Historical에서 서빙된다.
<Balancing Segment Load>
Coordinator는 전체 Historical 내 Segment들의 크기를 확인함에 따라 밸런싱을 수행한다.
밸런싱을 위해 Highest Utilization과 Lowest Utilization Historical을 찾고 Threshold 값에 따라 이동시킬 Segment를 정한다.
이 때, Segment는 랜덤으로 이동될 Historical이 정해지는데 이는 이동 후 Utilization이 감소될 때까지 반복해서 탐색된다.
<Compacting Segments>
쿼리 성능을 향상시키기 위해서는 작은 크기의 이웃한 Segment들을 합쳐줄 필요가 있다.
Compaction Task를 통해 Segment를 Merge하는데 Task의 수는 아래와 같이 정해진다.
min(sum of worker capacity * slotRatio, maxSlots)
Compaction 대상이 되는 Segment는 인접하면서 Segment 크기의 합이 설정된 SegmentSize 미만인 경우에만 해당된다.
이 때, skipOffsetFromLatest 옵션으로 최근 Segment의 경우 Realtime Task와 Compaction Task 간 충돌을 방지해야 한다.
Segment 크기는 다른 분산 처리 환경의 고려점과 동일하게 Segment 크기가 너무 큰 경우에는 Data 서버군 내 분포의 불균형이 발생할 수 있으며, Query 처리 시 병렬 처리 이점을 감소시킨다.
반면, Segment 크기가 너무 작은 경우에는 Query 당 해당되는 Segment 수가 너무 많아 스케줄링 오버헤드로 성능이 저하된다.
'Development > DB' 카테고리의 다른 글
| Apache Druid Ingestion (0) | 2019.12.31 |
|---|---|
| Apache Druid Architecture (0) | 2019.12.29 |
| Apache Druid 개요 (0) | 2019.12.29 |
| PostgreSQL에서 CSV 파일 Import하기 (0) | 2017.01.05 |

나뷜나뷜